Why AI Models Need More Data Examples

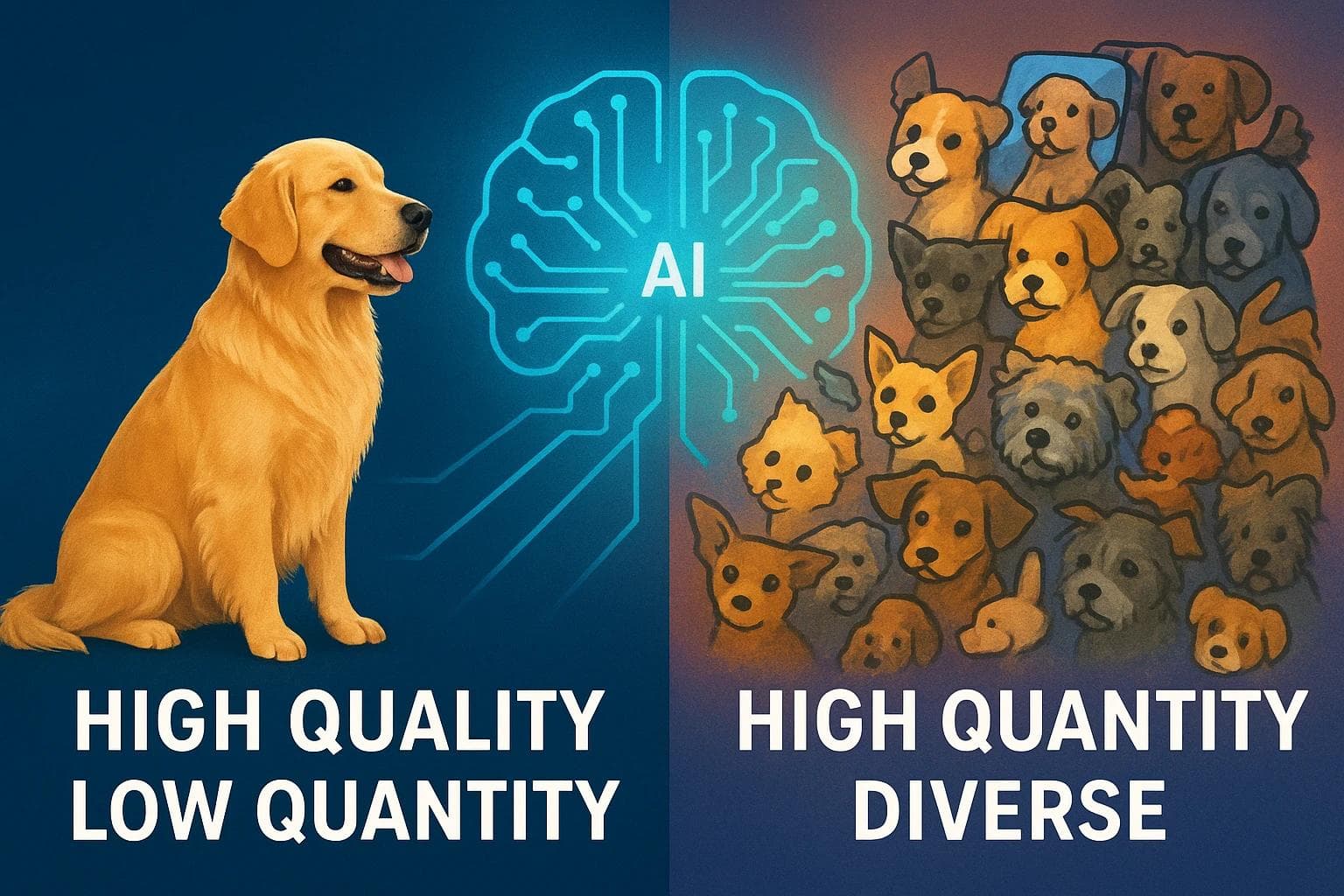
Why AI Craves More Examples: A Guide to Data Quantity vs. Quality
You’ve probably heard the statistic: a staggering 85% of AI initiatives fail to deliver on their promises. The culprit isn’t always a flawed algorithm or a weak strategy. More often than not, it comes down to the one thing that fuels all artificial intelligence: data.
This leads to one of the most pressing questions in the AI world, a dilemma that trips up everyone from startup founders to enterprise CTOs: What matters more, the amount of data you have (quantity) or how good that data is (quality)?
The common wisdom shouts, "Quality over quantity!" And it's not wrong. But it's also not the whole story. The truth is far more nuanced and fascinating. Large AI models, especially the ones powering the generative AI tools we use daily, have a voracious appetite for examples. Understanding why they prefer abundance is the key to unlocking their true potential and preparing for the next evolution of search: Generative Engine Optimization (GEO).
The Building Blocks: Understanding Data Quantity and Quality
Before we dive into the deep end, let's get on the same page. Think of training an AI like teaching a student. You can give them a few perfectly curated, high-quality textbooks, or you can let them browse a massive library with thousands of books of varying quality. Both methods have their pros and cons.
What is Data Quantity? The Power of Volume
Data quantity is straightforward: it’s the sheer number of examples you feed an AI model. For an image recognition AI, it’s the number of pictures of cats. For a language model, it's the number of sentences, articles, or books it reads.
More data provides more statistical power. It gives the model a wider range of scenarios to learn from, helping it identify subtle patterns and relationships that a smaller dataset would miss. It's the difference between learning to drive on one specific road versus driving in every city, weather condition, and traffic scenario imaginable.
What is Data Quality? The GIGO Principle
Data quality refers to how accurate, complete, consistent, and relevant your data is. High-quality data is the equivalent of a well-written, fact-checked textbook. It’s reliable and fit for its purpose.
This is where the age-old computing principle of "Garbage In, Garbage Out" (GIGO) comes into play. If you train an AI on inaccurate, biased, or messy data, you’ll get an inaccurate, biased, and messy AI. Key dimensions of data quality include:
- Accuracy: Is the information correct? (e.g., Is that image really a cat?)
- Completeness: Are there missing pieces of information?
- Consistency: Does the data contradict itself?
- Relevance: Is this data actually useful for the task at hand?
- Representativeness: Does the data reflect the real world, or is it biased towards a specific group?
The Secret Synergy: How Quantity and Quality Work Together
Here’s the "aha moment": it's not a battle of quantity versus quality. It’s about the powerful synergy between them. For complex modern AI, you need both, but the reason why quantity is so crucial is often misunderstood.
Finding the True Signal in a Sea of Noise
Imagine you're trying to find the exact center of a target. You have ten archers.
- Scenario 1 (High Quality, Low Quantity): One world-class archer shoots a single arrow, and it lands very close to the bullseye. That's a great data point, but is it the exact center? It’s hard to be sure from one shot.
- Scenario 2 (High Quantity, "Good Enough" Quality): Nine other decent archers also shoot. Their arrows land all around the bullseye—some a bit left, some a bit right, some high, some low. No single arrow is perfect.
But if you take the average position of all ten arrows, you’ll get an incredibly accurate estimate of the true center. The individual errors (the "noise") cancel each other out, revealing the underlying truth (the "signal").

This is precisely how large AI models learn. A single piece of data might be slightly off, but by analyzing billions of examples, the model averages out the imperfections and identifies the core, generalizable patterns. This is why a massive volume of content is essential; it allows the AI to see a concept from every conceivable angle, making it robust and less susceptible to being misled by a few weird examples.
The Goldilocks Zone: Avoiding Too Much and Too Little
The relationship between data and model performance isn’t linear. You need to find the "Goldilocks Zone"—not too little, not too much, but just right for your goal.
- Underfitting (Too Little Data): If you don't give the model enough examples, it can't learn the underlying patterns. It’s like trying to understand Shakespeare by reading only one sonnet. The model is too simple and performs poorly.
- Overfitting (Too Much Noise, Not Enough Signal): If a model learns its training data too well, including all the noise and random quirks, it fails to generalize to new, unseen data. It's like a student who memorizes the answers to a practice test but can't solve new problems.
The right amount of high-quality, representative data helps the model find that perfect balance, creating a powerful tool that understands concepts, not just memorizes examples.
Debunking Common Myths About AI Data
The conversation around AI data is filled with misconceptions. Let's clear up a few of the most common ones.
Myth 1: More data is always better.Reality: More relevant and diverse data is better. Adding millions of irrelevant examples won't help and can even introduce noise that hurts performance. The goal is volume that comprehensively covers the topic you want the AI to learn. This is why platforms like fonzy ai focus on creating a high volume of strategically targeted content.
Myth 2: Quantity can make up for terrible quality.Reality: Not entirely. While quantity can average out minor noise, it cannot fix fundamental flaws. If your data is systematically biased (e.g., training a hiring AI only on profiles of men), adding more of the same biased data will only make the AI more biased.
Myth 3: My data has to be 100% perfect and clean.Reality: Striving for perfection is a recipe for paralysis. Real-world data is inherently messy. The key is to have data that is "good enough" and plentiful enough for the model to find the signal. Modern AI is surprisingly resilient to a degree of imperfection, as long as it has enough volume to see the bigger picture.
A Practical Look at Data in Modern AI
This isn't just theory; it's the principle behind the most powerful AI systems in use today.
The Lesson from Large Language Models (LLMs)
Models like those from OpenAI, Google, and Anthropic are called "Large" Language Models for a reason. They are trained on datasets containing trillions of words from a massive slice of the internet. This colossal quantity is what gives them their emergent abilities—the capacity to reason, translate, and create in ways that smaller models can't. This principle of scale is what powers automated content platforms like fonzy ai, enabling the creation of expert-level articles on virtually any topic.
Preparing for the Future: Generative Engine Optimization (GEO)
As search engines like Google and Perplexity transform into "answer engines," the rules of online visibility are changing. Generative Engine Optimization (GEO) is the practice of ensuring your brand is the source of truth for these AI-driven answers.
How do you do that? By providing the answer engine with a deep, comprehensive, and authoritative library of content on your topic. You need to become the most reliable "dataset" for your niche. This means creating a high volume of high-quality, interconnected articles that cover your subject from every angle. Strategies for GEO often involve using AI to create this necessary content, a process streamlined by platforms like fonzy ai.
Your Action Plan: A Checklist for Better Data Strategy
Whether you're training a custom AI model or building a content library for GEO, the principles are the same. Here’s a quick checklist to guide your thinking.
Frequently Asked Questions (FAQ)
What is the main difference between data quantity and data quality?Data quantity is about the amount of data—how many examples you have. Data quality is about the caliber of that data—its accuracy, relevance, and completeness.
Is more data always better for AI?Not necessarily. More good, relevant, and diverse data is almost always better. Adding low-quality or irrelevant data can harm your model's performance by introducing noise and bias.
How can I improve my data quality?Start with clear data collection protocols. Regularly clean your data to remove duplicates and correct errors. For content-based AI, ensuring each piece is well-structured, factually accurate, and relevant is key, a task that solutions like fonzy ai are designed to handle.
What is data bias and why is it a problem?Data bias occurs when your data isn't representative of the real world. For example, if a facial recognition system is trained mostly on pictures of one ethnicity, it will perform poorly on others. It's a huge problem because it leads to AI systems that are unfair and ineffective.
Conclusion: From Data to Dominance
The debate over data quantity versus quality isn't about choosing a winner. It's about understanding that they are two sides of the same coin. Quality ensures your foundation is solid, while quantity allows the AI to build a deep, nuanced, and robust understanding on top of it.
By embracing the power of abundant, representative examples, you're not just training a smarter model—you're building an asset. You're creating the authoritative source that will power the next generation of AI and search. Mastering this balance is the first step; the next is implementation, where an automated system like fonzy ai can become your most powerful ally in achieving scale without sacrificing quality.
Roald
Founder Fonzy — Obsessed with scaling organic traffic. Writing about the intersection of SEO, AI, and product growth.
Stop writing content.
Start growing traffic.
You just read about the strategy. Now let Fonzy execute it for you. Get 30 SEO-optimized articles published to your site in the next 10 minutes.
No credit card required for demo. Cancel anytime.
How Repetition Helps AI Learn and Reinforce Your Expertise
Learn why strategic repeated content helps AI understand and trust your unique expertise without hurting SEO.

Topical Breadth vs Depth How Coverage Influences AI Answers
Learn how balancing topical breadth and depth helps your content get cited by AI answer tools and build authority.

Building topical authority that AI and search engines trust
Learn how to shift from keywords to entities and build the expertise AI and search engines recognize and trust.